Linear Regression and Assumption Validity
When designing a single or multiple linear regression model, a number of assumptions that support the integrity of that model. Some sources enumerate these as few as three, while other sources require as many as ten, though with some interpretation, these can be viewed as being contained under the umbrella of 4 wider categories.
Regardless of how we could these conditions, without them, a model may have fundamental flaws. These include, but aren’t limited to, misrepresentation of model fit, or disproportionate weight to certain regression coefficients.
Let’s take a look at these assumptions/, and a few useful tools to help investigate those assumptions.
- Linearity — there is a linear relationship between each predictor variable and the target/response variable. The easiest way to detect this is using a scatter plot (or box plot for categoricals) of each predictor vs the target. If it appears the points could fall along a generally straight line, its safe to proceed. If there are clear non-linear patterns (e.g. polynomial, exponential, or logarithmic curve shapes) then it is possible to feature-engineer a new column (e.g. apply a non-linear transformation) for the appropriate relationship, or to use a built in package to implement polynomial regression.
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
axes[0].set_title(‘Grade Counts’)
sns.countplot(df[‘grade’], ax=axes[0], color=’cyan’)
axes[1].set_title(‘Grade vs. Price’)
sns.boxplot(x=’grade’, y=’price’, data=df, ax=axes[1])
plt.tight_layout()

2. Normality of residuals — the residuals should exhibit a normal distribution. This is easiest to detect by inspecting a QQ-plot of residuals and a residuals vs dependent variable plot.
import statsmodels.stats.api as sms
import scipy.stats as stats
plt.style.use(‘ggplot’)
model = model_results2
resid1 = model.resid
fig = sm.graphics.qqplot(resid1, dist=stats.norm, line=’45', fit=True)

Departure from linearity in the QQ-plot indicates deviations from normality. If the QQ plot deviates at one end or the other, it is possible to exclude those observations from the model, refit the model, and regain normality of residuals.
Curvature in the residuals vs. dependent variable plot would indicate an underlying non-linear relationship between independent and dependent variables.
3. Homoscedasticity of residuals — the residuals should exhibit consistent variance across the values of the dependent variable. The issue with this phenomenon would be that regions with low variance would gain the model credence, offsetting regions with unacceptably high variance, resulting in a misleadingly high R² score.
In a residuals vs. dependent variable scatter plot, there should be no notable fan/cone shape. Presence of such a fan shape would indicate heteroscedasticity. (See the upper right plot below)

(after having fit a statsmodels model as variable “model”)
fig = plt.figure(figsize=(15,8))
fig = sm.graphics.plot_regress_exog(model, predictor_column, fig=fig)
plt.show()
In addition to inspection of the residual vs. dependent plots, there are also some numerical tests, like Goldfeld-Quandt test for homoscedasticity or the Breusch-Pagan test for heteroscedasticity, both implemented in statsmodels.
import statsmodels.stats.api as sms
name = [‘F statistic’, ‘p-value’]
test = sms.het_goldfeldquandt(model.resid.iloc[indices], model.model.exog[indices])
list(zip(name, test))
from statsmodels.stats.diagnostic import het_breuschpagan
(v1, v2, v3, v4) = het_breuschpagan(model.resid, model.model.exog, robust=True)
In the event that heteroscedasticity appears, it can often be addressed by applying a log transformation of the dependent variable if possible, or applying a scaling to the independent variable(s).
4. Independence of observations, variables, and residuals— Observations examples of violations of these assumptions include multicollinearity (for observations) or dependence of time-adjacent samples in a time-series (for residuals).
Non-independence of observations can be avoided primarily by design and inspection of the data collection process; including careful experimental design.
Non-independence of residuals is of most concern in a time-series analysis. The Durbin-Watson test is a powerful tool to check for non-independence of adjacent residuals.
Finally, non-independence of variables can be checked by:
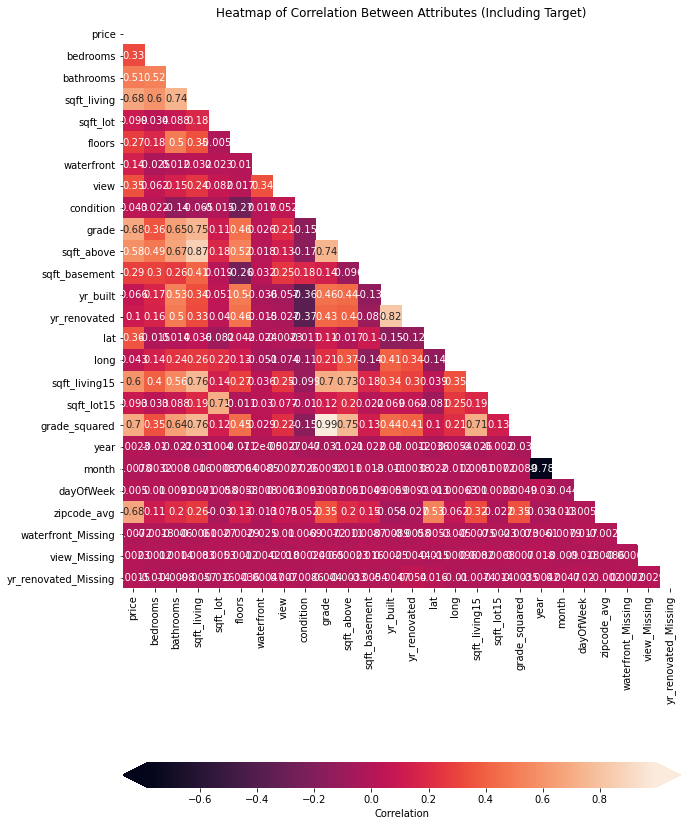
- Creating a correlation matrix and verifying that there are low correlation values between independent variables
- corr = heatmap_data.corr()
- # Set up figure and axes
fig, ax = plt.subplots(figsize=(10, 16)) - # Plot a heatmap of the correlation matrix, with both
# numbers and colors indicating the correlations - sns.heatmap(
data=corr,
# The mask means we only show half the values,
# instead of showing duplicates. It’s optional.
mask=np.triu(np.ones_like(corr, dtype=bool)),
ax=ax,
# Specifies that we want labels, not just colors
annot=True,
# Customizes colorbar appearance
cbar_kws={“label”: “Correlation”, “orientation”: “horizontal”, “pad”: .2, “extend”: “both”}
)
# Customize the plot appearance
ax.set_title(“Heatmap of Correlation Among Attributes Including Target”);
- Using Variance Inflation Factor analysis — a VIF above 5 should be cause for further consideration and a VIF above 10 is a strong indicator of multicollinearity.
from statsmodels.stats.outliers_influence import variance_inflation_factor
X = predictor_columns #from our dataset — exclude the target column
x_cols = predictor_columns.columns
vif = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
list(zip(x_cols, vif))
Output:
[(‘bedrooms’, 1.8682394117519536),
(‘bathrooms’, 3.3775310246827908),
(‘sqft_living’, 38.49770881243451),
(‘sqft_lot’, 7.116782506203766),
(‘grade’, inf),
(‘sqft_above’, 31.497959011803264)] - Checking the Condition index, which is supplied in the model summary of the Python statsmodels module. Statsmodels also conveniently provides a warning near the bottom of the summary if it detects a Condition value that would indicate multicollinearity.
(for help on building a ordinary least squares linear regression, see documentation for statsmodels.formula.api.ols . Once model is fit, running model.summary() will give output with a lot of information. For the purpose of investigating multicollinearity, look near the bottom for Cond. No. along with any notes with bracketed numbers below that that warn of multicollinearity.
If multicollinearity is detected, removal of one of the offending variables is usually a direct and effective approach.
https://medium.com/@ericthansen/linear-regression-and-assumption-validity-94712f714ea4